За по-малко 10 минути 11-годишният Емет Брюър е успял да хакне системата за публикуване на резултатите от гласуване в американския щат Флорида. Постижението му е станало по време на 26-тото издание на конференцията DEFCON в Лас Вегас.
Самото състезание е организирано специално за деца, тъй като (според организаторите) „никой възрастен хакер не би се съгласил, тъй като е твърде лесно“.
Нико Сел – един от организаторите и създател на организацията r00tz Asylum за малки хакери – сподели, че друго 11-годишно момиче се е справило в рамките на 15 минути. Сел сподели и друга подробност от резултатите – 30 от 50-те деца са се справили със задачата за под 30 минути.
Важно уточнение е, че децата са се опитали да пробият защитата на реплики на сайтовете и мерките им за сигурност, а не на оригиналните такива.
„Това са много точни реплики на уебсайтовете. Не би трябвало проникването в тях да е толкова лесно за 8-годишно дете с половин час свободно време. Това е безотговорно от наша страна като общество“, коментират организаторите
След състезанието последва изявление от правителството на САЩ:
Уебсайтовете безспорно имат уязвимости. Все пак е невероятно трудно да се направи реплика на сайта с точната база данни и мрежови мерки за сигурност в момента“. В изявлението се казва и че тези сайтове служат за съобщаване на резултатите, а не за техния пряк брой.
На това твърдение организаторите на събитието отговориха, че дори и промяната им козметично може да доведе до достатъчно вреда и хаос и че правителството трябва да обърне по-сериозно внимание на резултатите от състезанието.
Похватите за амплификация и отразяване (amplification and reflection) са едни от най-често използваните при изпълнение на DDoS атаки. Благодарение на настройките си по подразбиране и/или „лоши“ конфигурации, протоколите и услугите като DNS, NTP, SSDP и Memcache се превръщат в опустошителни вектори за атака. В сравнение с традиционните методи за изпълнение на DDoS атаки, а именно създаване на многобройна botnet мрежа от IoT и мобилни устройства, каквито са Mirai, Hajime и WireX, вече споменатите услуги предоставят възможност за достигане на далеч по-обемни (~2Tbps) атаки с много по-малък брой уязвими сървъри. Как? Използваният транспортен протокол (UDP) е идеален за целта, като фактора на амплификация достига до 50 000, в зависимост от приложението:
За scrubbing услуги, предоставяни от големите доставчици като Google, CloudFlare, Akamai и Imperva, не представлява проблем да се справят с атаки от такъв тип. Обема на зловредния трафик не е важен, защото изходния порт (source порта) в хедърите на амплифицираните пакети следва предсказуем модел, примерно филтрацията на пакети с изходен порт 53 при DNS атака е стандартна мярка.
Вече не може да разчитаме на това
Именно от Imperva оповестиха откритията си относно иновативния метод за маскиране на традиционни DDoS атаки. Наскоро те са противодействали на SSDP амплифицирана атака, при която са забелязали пакети с нестандартен начален порт – нещо, за което досега се смяташе, че едва ли е възможно, камо ли някой да е готов да се защитава от такава атака.
На база първоначална хипотеза, Imperva успяват да създадат Proof-of-Concept за изпълнение на замаскирана DDoS атака, като използват UPnP (Universal Plug and Play) експлойт.
UPnP е протокол с дълго минало и множество проблеми касаещи сигурността
За незапознатите, UPnP е мрежов протокол опериращ върху UDP на порт 1900 за откриване на други устройства и случайно избран TCP порт за управление. Протокола има широко приложение в IoT устройствата (компютри, принтери, рутери и други), като служи за взаимното им откриване в LAN мрежата.
Какви са евентуалните проблеми с UPnP:
В някои имплементации настройките по подразбиране предоставят отдалечен достъп през WAN;
Липсва оторизиращ механизъм, което в комбинация с първата точка влошава положението сериозно;
Съществуват уязвимости предоставящи възможност за отдалечено изпълнение на код.
Исторически погледнато, първото разглеждане на слабости в UPnP е през 2001 с откриването на buffer overflow exploit. След това през 2006 е публикувана статия с интересното име – „Universal Plug and Play: Dead Simple or Simply Deadly“. В нея са описани методи за отдалечена пренастройка на устройства поддържащи UPnP чрез XML SOAP API съобщения.
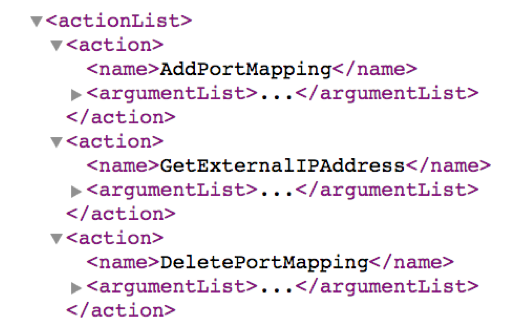
От Rapid7 и Akamai също отделят време да изследват възможностите за експлоатиране на тази технология. През 2015 година по време на DEF CON 23, Ricky Lawshae изнася интересна презентация на тема UPnP и SOAP съобщения. В нея се отделя специално внимание на факта, че е възможно отдалечено изпълнение на AddPortMapping команди, които от своя страна управляват логиката за пренасочване на портове.
Маскиране на DDoS атака чрез UPnP пренасочване на портове
В описаната от Imperva SSDP атака, анализаторите са открили, че около 12% от пакетите идват от неочакван изходен порт, а не от UDP/1900. След оценка на няколко възможни опции, те успяват да пресъздадат атака, при която независимо типа на амплифицираният протокол, изходните портовете биват замаскирани.
Как би изглеждала евентуална подготовката за стартиране на DNS маскирана DDoS атака?
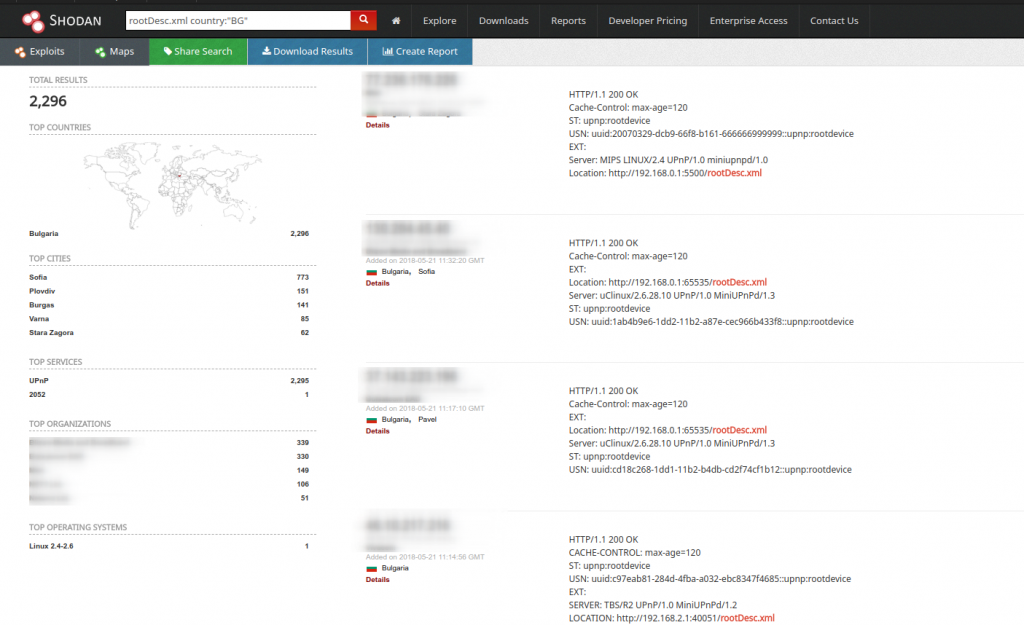
Откриване на общодостъпни UPnP устройства С помощта на IoT търсачката shodan.io, резултатът за българското пространството
За сравнение, в световен мащаб и към момента на публикуване на тази статия, точният брой е 1,365,553. Това по никакъв начин не означава, че всички тези устройства са уязвими, но намирането им измежду множеството не представлява проблем за мотивираните престъпници.
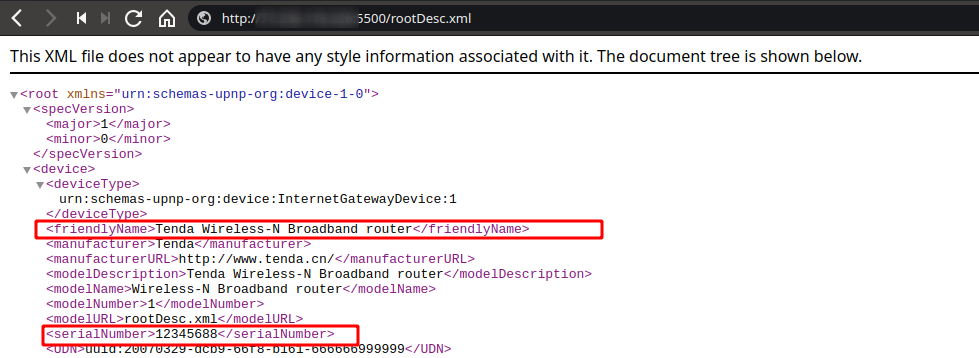
Ето така изглежда XML който UPnP сервира
Промяна на правилата за пренасочване на портове В rootDesc.xml са описани всички предоставяни услуги и свързани устройства, където по секцията <SCPDURL> могат да се видят действията, които устройството ще приеме отдалечено. В началото на списъка виждаме вече споменатото действие – AddPortMapping, което позволява конфигурирането на пренасочващи правила. Използвайки схемата на XML файла, може да бъде създаден SOAP запис, който да пренасочи всички UDP пакети от порт 1337 към публичен DNS сървър (3.3.3.3) на порт UDP/53. За повечето от нас, това пренасочване няма смисъл и дори очакваме да не сработи! При port forwarding правилата се прави връзка от публични (външни) към частни (вътрешни) IP адреси Source и обратното, а не се прави proxy заявка от външно към друго външно IP. Всъщност, много малко рутери имплементират такъв тип проверка, при който удостоверяват, че предоставеното вътрешно IP наистина е вътрешно.
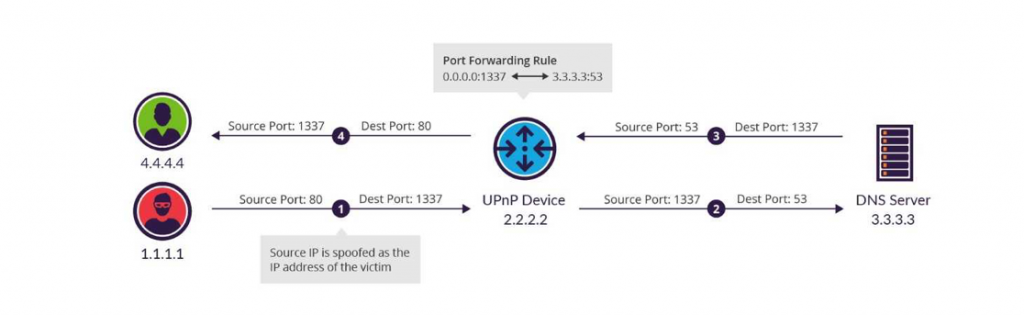
Стартиране на замаскираната атака С направеното до тук, атаката следва следният сценарий:
Уязвимият рутер получава DNS заявка на UDP/1337;
Заявката е пренасочена към DNS сървър с краен (destination) порт UDP/53, благодарение на правилото за пренасочване;
DNS сървъра отговаря на заявката като със sourse port UDP/53;
Рутера предава отговора на DNS сървъра към първоначалният заявител, но не и преди да смени source порта обратно към UDP/1337.
Source: Imperva
В случая престъпникът (1.1.1.1) се представя (spoof) от името на жертвата – така усилените и замаскирани пакети достигат до крайната точка (4.4.4.4)
Описаната техника важи за всички протоколи и услуги, които така или иначе се използват за DDoS атаки, но с нея вече не може да се разчита на филтрация на база source IP и port. Така стандартните защитни механизми стават ненадеждни, като най-вероятна технология за защита от такива атаки е Deep Packet Inspection (DPI), която от своя страна изисква много повече ресурси и е предизвикателство да обработва in-line трафик без значителна инвестиция.
Истинското решение на проблема е такива устройства да не бъдат публично достъпни и да филтрираме достъпа до тях. Mерки, които често биват пренебрегвани, понеже реално не предоставят реални ползи за техните ползватели.
На 28 февруари станахме свидетели на най-мащабната DDoS атака в историята на интернет. Добре познатия на всички сайт за хостване на проекти на разработчици GitHub попадна от лошата ѝ страна и принудително бе спрян, макар и за кратко.
Обемът на атаката е измерен на 1.35 Tbps (терабита в секунда), постигнати чрез средно 126.9 милиона пакети в секунда.
За атаката не е използвана ботмрежа, а много по-прост и лесен за експлоатация метод – използването на отговори от Memcached сървъри.
Нова механика за блокиране
Най-интересното в случая е самата механика зад атаката. Тя няма нужда от дистрибуцията на зловреден код до стотици хиляди устройства. Вместо това, авторите ѝ се възползват от лошо подсигурени и публично достъпни Memcached сървъри – машини, които оптимизират работата на бази данни като запомнят най-често достъпваната информация в RAM паметта си. Освен това, те имат и друга особеност – заявка от едва няколко байта може да получи отговор в размер на стотици килобайти.
По този начин, всеки атакуващ може да изпрати малък брой заявки към различни Memcached сървъри и да замени IP-то на изпращача с това на фирмените ви сървъри. Така вие ще получите огромен обем данни, усилен от неправилно внедрената UDP функционалност на Memcached услугата. Това дава и името на този тип атака – amplification attack (атака чрез усилване).
Защо е разумно да очакваме още такива инциденти
Въпреки че amplification атаките не са нищо ново, тази използва хиляди неправилно конфигурирани сървъри, за да изпълни целите си.
„Предимството“ на този вектор е, че е достъпен – няма мрежи за поддръжка и няма нужда от заразата на стотици хиляди машини, за да се достигне достатъчно голям обем от трафик. Като много други, той разчита на грешките в човешкия фактор.
Не е ясно на колко по-мащабни атаки ще станем свидетели докато се изчисти проблемът с публично достъпни memcached сървъри. Заради това е нужно да се действа сега – като скролирате до края на статията.
Съвети за потребители, системни администратори и разработчици
IP spoofing-a все още е разрешен от голяма част от интернет доставчиците, а филтрирането на фалшифициран трафик на потребителско ниво е почти непосилно за повечето. Ако използвате Memcached е нужно да станете част от решението преди да станете част от проблема:
Обновете софтуера си – последната версия на решението забранява UDP комуникация поначало.
Ако използвате стара версия, можете да използвате–listen 127.0.0.1 при старт, за да накарате сървъра да „слуша“ изцяло локално или–U 0, за да забраните UDP изцяло.
Използвайте следните команди, за да тествате дали сървърът ви е уязвим – ако получите празен отговор, значи всичко е наред:
Поставете сървъра зад защитна стена и не позволявайте UDP или TCP достъп до него.
Използвайте описаните горе инструкции, за да забраните приемането на UDP пакети и да тествате за уязвимост. За да тествате TCP, можете да използвате nmap.
Разработчици:
Ограничете използването на UDP комуникация в софтуера си, особено незащитена чрез оторизация такава. Има редица примери за това защо не трябва да го правите – DNS, NTP, Chargen, SSDP, а сега и Memcached. Ако използвате UDP, то е задължително да връщате по-малки като размер отговори на потребителските заявки.
Уязвимост в неправителствената организация Let’s Encrypt и идеалната ѝ цел да осигури безплатни TLS сертификати на сайтове със споделен хостинг може да изиграе обратна роля – и вместо да помогне, да се превърне в проблем за сигурността на милиони интернет потребители. Причината: уязвимост, която при определени условия може да позволи издаването на сертификати за домейни върху споделен хостинг, от лица които нямат контрол върху тези домейни.
Какво е Let’s Encrypt и ACME?
Накратко – Let’s Encrypt започва като инициатива на ISRG (Internet Research Group). За да реализират инициативата, ISRG създават ACME (Automatic Certificate Management Environment) – протокол, който определя автоматизацията на процедурите между издателите на сертификати и уеб сървърите на потребителите им. Той използва три от т.нар. „10 благословени метода“ за потвърждаване на самоличността на притежател на домейн.
Методите са създадени заедно с група доброволно включили се производители и издатели на сертификати и са описани в документа „Baseline Requirements“ (секция 3.2.2.4).
За един от използваните – sni-tls-01– е открит начин да се експлоатира, в случай, че се използва от домейн, свързан със споделен хостинг.
Проблемът с ACME и споделения хостинг
Преди дни беше открита огромна уязвимост, която засяга всички, които използват Let’s Encrypt на споделен хостинг. Тя е осъществима чрез методите за потвърждение на самоличност на ACME и начинът, по който споделения хостинг работи. Cloud услуги като CloudFront и Heroku бяха също разкрити като уязвими, но чрез бърза реакция вече не позволяват експлоатирането на точно тази уязвимост.
Дупката в сигурността позволява на атакуващ да издава сертификати за външни домейни чрез споделен хостинг и в последствие да ги използва за предоставяне на вредно съдържание.
Какво значи това за нас?
За момента е спряно издаването на сертификати чрез tls-sni-01 и следващата му версия – tls-sni-02, както се споменава в официалното изявление на Let’s Encrypt. Всички cloud-based доставчици на хостинг също трябва да предприемат стъпки за „запушването“ на този пробив във сигурността, след като водещите такива откликнаха.
По-добри ли са платените сертификати?
Допускането на толкова сериозен пробив във сигурността може да накара някои хора да си кажат „за толкова пари – толкова“. Нужно е, обаче, да погледнем към сигурността на платените услуги – наистина ли е по-добра. Отдолу можете да видите изброени няколко инцидента, които ще ви дадат достатъчно ясна представа:
Светът се сблъска с две от най-мащабните (и като обхват, и като ниво на опасност) уязвимости в историята си – Meltdown и Spectre. Пропуските в дизайните на процесите на Intel, AMD, Qualccomm и още десетки производители позволяват кражбата на чувствителна информация без знанието на потребителите – и без те дори да разберат. И докато технологичните подробности далеч не са за пренебрегване – то ето какво може да направите, за да се предпазите от ефектите на двете уязвимости – както и устройствата, които са засегнати от тях.
Историята, накратко
Meltdown и Spectre бяха „разкрити“ в тема сайт за споделяне на съдържание – reddit.com. Темата, наречена „Intel bug incoming” твърдеше, че процесорите на Intel, произведени през последните 10 години, са засегнати от критична уязвимост.
На преден план излиза това, че чрез експлоатация на една от функциите за ускоряване на работата на процесора, даден процес може да достъпи информация, която не би трябвало да бъде достъпна за него. Това се дължи на факта, че има пролука между пространството на паметта, където се изпълнява потребителски софтуер (user-mode address) и това, в което се съхраняват пароли, сертификати, криптографични ключове и др. (kernel-mode address). По този начин, зловреден код може целенасочено да достъпи до информация, запазена само за специфични процеси с право на достъп до нея.
Двата основни вектора за атака получиха имената Spectre и Meltdown.
Положението към момента
Засега са ясни следните неща:
Всички видове процесори са засегнати донякъде. От ARM процесора на телефона ви, до IBM процесорите в суперкомпютрите
Добавянето на допълнителен слой сигурност може да доведе до забавянето на производителността на процесорите с между 5% и 30%
Най-засегнати от уязвимостите са продуктите на Intel, което ще направи и забавянето им по-осезаемо след патчване
До момента, при откриването на уязвимост или бъг в процесор, производителя му я поправя чрез т.нар. „микрокод“. Поради една или няколко все още неясни причини, „запушването“ на Meltdown и Spectre не може да се случи по този начин. Това накара производителите на процесори, заедно с тези на операционни системи, да работят по отстраняването на опасността на софтуерно ниво.
Засегнати производители
Ето част от засегнатите производители – и мерките, които те са предприели за решаването на проблема.
Засега най-добрия ви вариант за навременна реакция е да следите новините от производителите, чиито процесори използвате, и потребителската общност, както и да се осведомите за бъдещи обновления за операционната ви система.
Информация за системни администрартори
Meltdown и Spectre са толкова комплексни като уязвимости, че е трудно решението им да бъде обобщено в един абзац или няколко реда. Въпреки това, имаме няколко полезни съвета и други материали:
Опознайте уязвимостите, за да разберете как да се пазите от тях. Например, туккакто и ето тук. Блогът на Raspberry Pi има опростено обяснение на техническите специфики около уязвимостите – можете да го намерите тук
Можете да намерите много по-подробна информация за всеки производител на хардуер и софтуер относно уязвимостите в това github repository
Таблица с информация за това дали антивирусния ви софтуер предотвратява обновленията на операционната система и дали и как можете да го поправите можете да видите в Google Drive
Скриптове, които ви позволяват да проверите дали сте засегнати от уязвимостите можете да намерите за Linux и Windows
Обновявайте софтуера на всички ваши устройства и следете за подозрителна активност
В последно време се убедихме, че потребителят действително е най-слабото звено в системата на информационна сигурност на една компания. Без значение дали става дума за откуп, фишинг или кражба на лични данни, изглежда, че винаги има намесен служител, който волно или неволно отваря вратите за киберпрестъпниците.
Служителят е най-слабото звено
Хакерите разчитат все повече на обикновените потребители в една система, за да получат нерегламентиран достъп до нея. Скорошно проучване показа, че всяка втора фирма на запад е била жертва на ransomware през последните 12 месеца, а повечето компании са претърпели един или друг киберпробив в системата си. България не е изключение от тази статистика. Да си припомним случая с фалшивия имейл от НАП, съдържащ архивен файл с троянски конNemucod, който подканваше потребителите да се запознаят с промени в регламента за подаване на приходни декларации. Разархивиране на прикачения файл на офисен компютър води до задействане на вируса, който от своя страна започва да тегли и инсталира други зловредни кодове, потенциално компрометирайки цялата система.
В повечето случаи в България и в чужбина, грешка от страна на служителя води до създаване и експлоатиране на уязвимости. Но именно фактът, че това се дължи на човешко действие прави тези вид заплахи толкова трудни за преодоляване.
Какви действия да предприемем, за да предпазим бизнеса си от човешка грешка?
Най-доброто решение за опазване на корпоративната инфраструктура от човешка грешка е превенцията, а отговорността за взимането на предпазни мерки е в ръководството на компанията.
Първата стъпка е въвеждането на корпоративни политики, които да са част от официалните правила на работа. Текстът трябва да е практичен, лесен за осмисляне и да съдържа най-често срещани случаи. Това ще увеличи шанса за спазване на правилата.
„Инвестирайте в трейнинги по информационна сигурност. Статистиката показва, че компаниите, чиито служители са преминали подобно обучение, са 75% по-малко уязвими спрямо останалите“, твърди Марк Брунели от американската фирма за криптирани облачни услуги Carbonite.
Експертът добавя, че това е най-ефективната „първа линия на защита“ срещу потенциална атака.
Третият подход, който препоръчват експертите е показването на съвети за поддържане на информационна хигиена по време на работа, например през push нотификации в Интранет или с имейл-напомняне към всички служители. Колкото по-често се показват тези съвети, толкова по-вероятно е те да бъдат следвани.
Ето пример за 5 простички правила, които всеки служител може да следва:
Не отговаряйте на подозрителни имейли
Няма случай, в който някой да има основание да ви поиска информация за потребителско име или парола! Не я давайте!
Не кликвайте върху подозрителни линкове и банери!
Ъпдейтвайте софтуера регулярно, включително и антивирусната си програма
Замислете се дали има основание да предоставяте лична информация, когато ви бъде поискана
Не на последно място по-напредналите мениджъри могат да поискат инсталирането на специални софтуери за превенция на загуба на информация (Data Loss Prevention [DLP]), които показват предупреждения в рискови случаи като изпращането на вътрешни документи към външни имейл адреси или използването на опасни програми и сайтове по време на работа.
Интегрирането на един или повече от тези подходи в работния процес ще намали значително риска от компрометиране на ключови бизнес процеси.
Събитията, които действително могат да сплотят една компания не са много. Падането на сървъра безспорно е едно от тях.
Запознайте се с петте най-ефективни начина да се предпазите от подобен инцидент.
1. Поддържайте сървъра
Навлизането на облачните услуги сред бизнес сегмента успя да намали ефекта от сървърните крашове, но със сигурност не успя да елиминира подобни случаи. И дори част от инфраструктурата да е в облака, в повечето случаи, бизнесът продължава да ползва физически сървъри. Да не говорим, че болшинството български компании изобщо не се възползва от облачни услуги. Ето защо поддръжката и профилактиката на сървърите е толкова важна.
Колкото и явно да ни се струва това, последните кибератаки с WannaCry и Petya ни доказаха, че дори и сериозни организации често забравят за тази на вид елементарна стъпка. WannaCry се оказа фатално ефективен защото се възползва от уязвимост в неъпдейтнати версии на Windows 7, но и от сървъри с Windows Server 2003. Затова е важно да се убедим, че компютрите и сървърите ни работят с активноподдържани от Microsoft операционни системи (никакви Windows XP и Server 2003).
Друг проблем е, че много от IT специалистите не искат и да чуват повече за сървърите веднъж настроили ги да работят правилно. Някои от тях достигат до абсолютно недопустими екстреми като изключват тотално процеса на автоматични ъпдейти на Windows. Да, тестването на пачове във виртуална машина (VM) отнема време, и да, Microsoft неведнъж е пускал бъгави пачове, но това не означава, че трябва съзнателно да държим операционните си системи неъпдейтнати, защото те непременно ще ни създадат главоболия един ден.
Най-новите версии на Windows дават повече контрол над това как и кога да се ъпдейтват операционните системи. Вижте тази статия за Windows Server 2016, за да се убедите сами.
3. Почиствайте сървъра
„Чакай, нали държа сървъра в затворено помещение?“
Браво, страхотно начало!
Още по-добро начало са сървърните поставки, рафтове и кабинети и подходящата микросреда. Но дори и в компанията, в която работите да има всичко това, сървърите неминуемо ще се пълнят с прах, а това води до намалена производителност и надеждност. Както всички знаем, съвременните процесори и видео карти автоматично намаляват производителността си, ако не получават адекватно охлаждане. За щастие висококачествените сървъри обикновено имат мощни перки за вентилация около критичните компоненти. Хайде, обаче, да се замислим какво друго прави една перка? Всмуква прах.
Ползвайте спрей с компресиран въздух, за да почистите внимателно сървърите, както отвън, така и отвътре. Внимавайте като впръсквате в перките. Разглобете и почистете отделно всеки един от филтрите, ако сървърната поставка има такива. Работете прецизно и търпеливо.
4. Качете сървъра на VM
Back-up сървър? Скъпо и неефективно. Виртуален сървър? Много по-добра идея.
Живеем във времена, в които можем да качим почти всеки сървър на VM, а това означава, че няма причина да не поддържаме копия на всичките си сървъри във виртуален вариант.
Освен, че е лесно, виртуалният сървър е далеч по-практичен от крепенето на още една купчина желязо в мазето на паркинга. Консолидацията на няколко стари сървъра в един виртуален сървър пък почти винаги ще доведе до повишена ефективност и пестене на време.
Ясно е, че не всички сървъри могат да бъдат виртуализирани заради лицензи, хардуерни пречки и други подобни, но това не е извинение да не качим тези, които могат да бъдат виртуализирани на VM.
За списък с това, което не трябва да виртуализираме, вижте тази статия.
5. Проверете за хардуерни проблеми
Дефектните компоненти са най-сигурният начин да пратим един сървър в гроба. Хардуерните грешки се проявяват най-често след POST (Power-on Self-test) процеса при стартирането на операционната система.. Проверете системните логове за хардуерни проблеми. Може да се окаже, че един обикновен ъпдейт на драйвърите решава проблема, а може и да се окаже, че нещо в сървъра е изгоряло.